
Des chercheurs de Stanford, le MIT ou encore de Harvard ont synthétisé, en fin d’année dernière, dans un rapport, un bilan des données sur l’Intelligence Artificielle pour l’année 2018 (à l’instar de ce qu’ils avaient déjà fait sur 2017 mais plus centré sur le continent américain pour la première édition).
Le rapport est téléchargeable via ce lien. Il est aussi consultable ici :
Il est composé de 4 parties principales :
- Volume d’activité qui recense les conférences, les éléments publiés, les projets disponibles sur GitHub, la couverture médiatique.
- Performances techniques notamment en Vision et en compréhension du Langage Naturel.
- Mesures dérivées et initiatives gouvernementales.
- Majeures évolutions de l’IA au travers d’une frise chronologique (en matière de capacité à égaler ou dépasser les compétences humaines, dans différents domaines comme le jeu, la médecine ou la traduction automatique).
Un dernier chapitre évoque ce qui manque dans ce rapport. En particulier, un passage a retenu mon attention sur l’Intelligence Artificielle Symbolique. En effet, alors que l’IA a commencé avec les modèles connexionnistes dans les années 50, elle a connu un second souffle avec les approches symboliques dans les années 80 mais celles-ci ont été occultées ces dernières années par le retour en force de l’IA connexionniste. Le rapport évoque la perspective intéressante d’étudier les combinaisons de Machine Learning et de l’IA symbolique. Je suis convaincu que c’est, en effet, une piste à examiner sans parti pris.
J’ai extrait du rapport 4 graphiques (mais il contient une multitude d’autres informations).
28% des papiers sur l’IA (sur Scopus) sont issus des pays européens, devant la Chine (27%) et les US (17%)
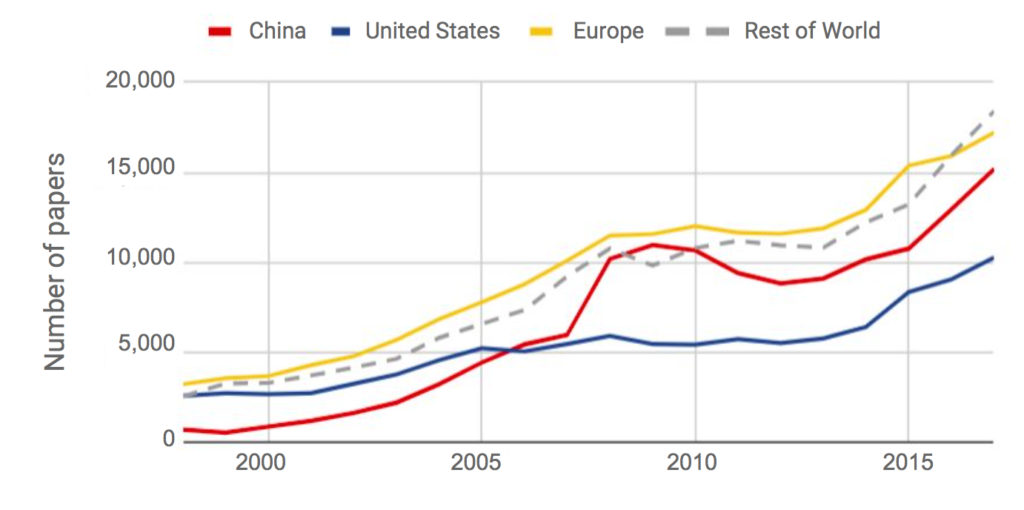
Cependant, la Chine a été le plus important pourvoyeur de publications lors de la dernière conférence AAAI en 2018 (et de très loin). L’impulsion gouvernementale est très forte dans ce domaine. 70% des publication soumises viennent de Chine et des US.

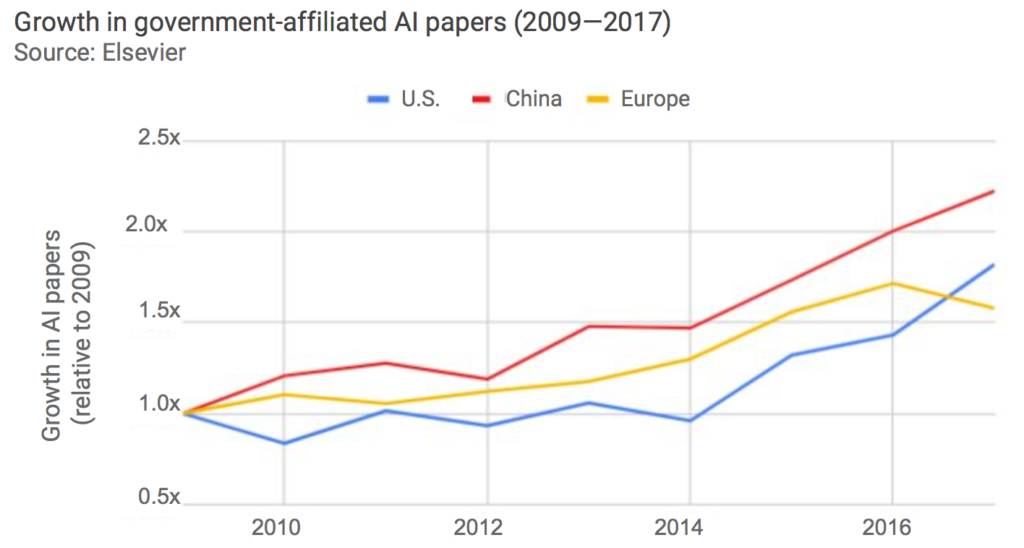
Cette stratégie nationale est visible dans ce graphique qui montre le doublement des publications « gouvernementales » (ou académiques) pour la Chine entre 2009 et 2017.
Côté performance, un graphique est significatif. Il confirme la puissance des machines et la capacité à traiter des données avec une rapidité de plus en plus efficace. En un an et demi, le temps d’apprentissage pour un réseau pour classer des images avec un degré donné de pertinence est passé de 1 heure à … 4 minutes.
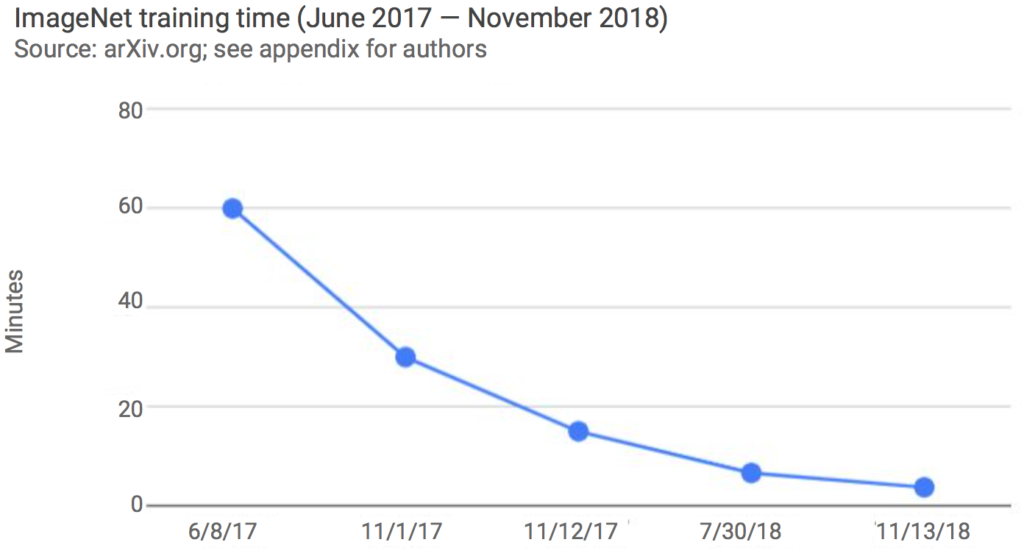
Si on cherchait à remonter encore plus le temps, la courbe serait bien plus impressionnante avec une limite vers l’infini (à gauche) puisqu’il y a quelques années, il aurait été impossible de réaliser l’apprentissage d’un réseau (ni même d’ailleurs de stocker les images à lui soumettre). La combinaison capacité de stockage et performance des processeurs permet ces résultats à algorithmes équivalents (mais ils ont de plus été optimisés et améliorés).
Une synthèse des initiatives gouvernementales est proposée en pages 57 et 58 du rapport en comparant les approches US vs Europe vs Chine.
Bonne lecture en attendant le bilan 2019…
PS : L’illustration de l’article vient, comme souvent, de Pixabay.


